| A Predicting Wave Heights from Floating Buoy Data | |||
|
Tyler Kim
|
|||
| Final project for 6.7960, MIT | |||
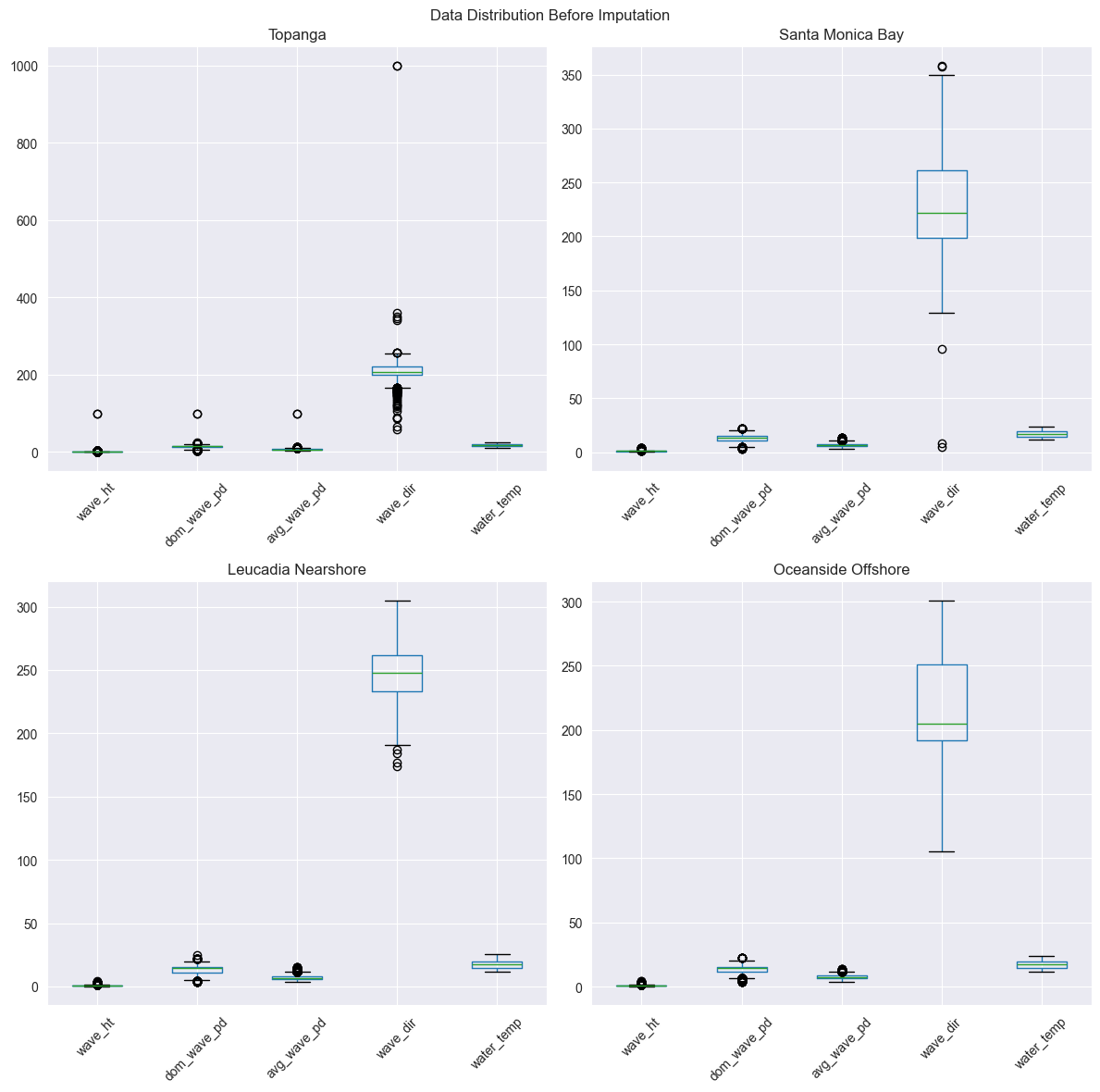
After dropping the missing values, we are left with:
There is a fair amount of periodicity, as well as some variability with seasons, such as a large spike in wave height at the start of January. This tracks relatively well with intuition, as swell waves are generated by storms throughout the Pacific Ocean during the winter months. [7]
- Wave Height
- Dominant Wave Period
- Average Wave Period
- Wave Direction
- Water Temperature
Data Exploration
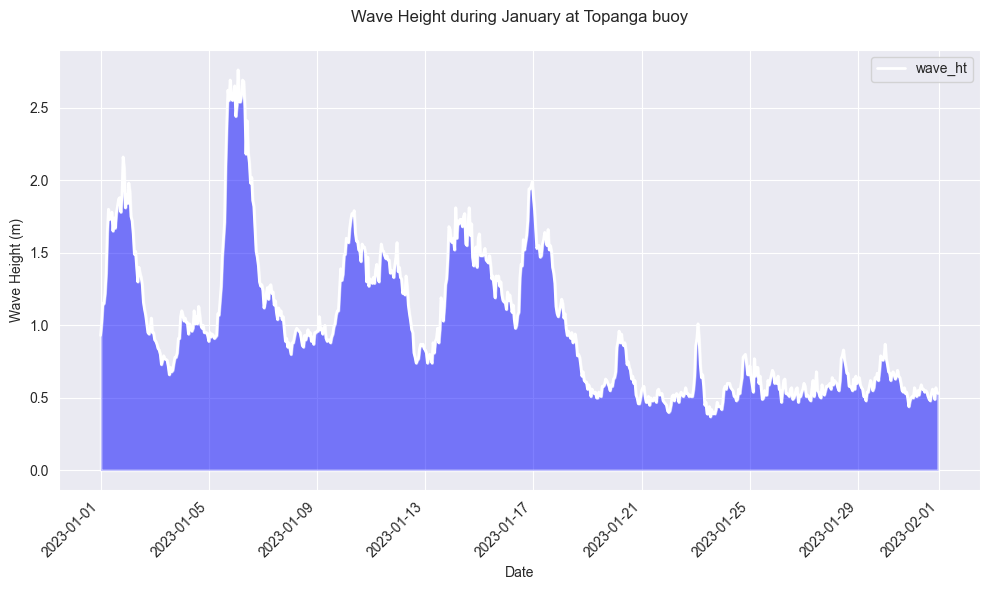
For the rest of the analysis, we are interested in predicting wave height. To understand the form of the target variable, a plot of wave height data from the Topanga buoy in the month of January 2023 is shown below:
There is a fair amount of periodicity, as well as some variability with seasons, such as a large spike in wave height at the start of January. This tracks relatively well with intuition, as swell waves are generated by storms throughout the Pacific Ocean during the winter months. [7]
Wave height data from Topanga buoy, for the month of January 2023.
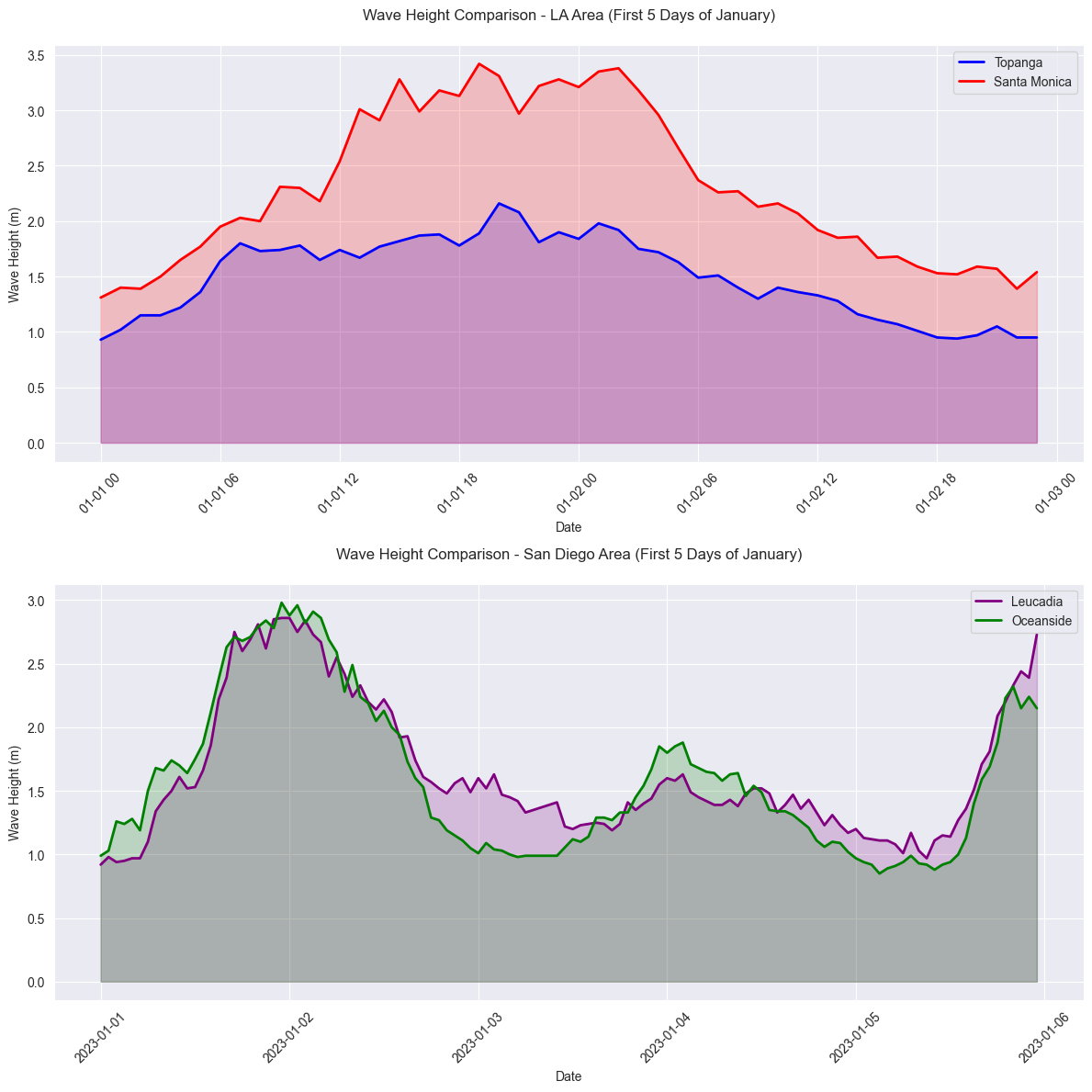
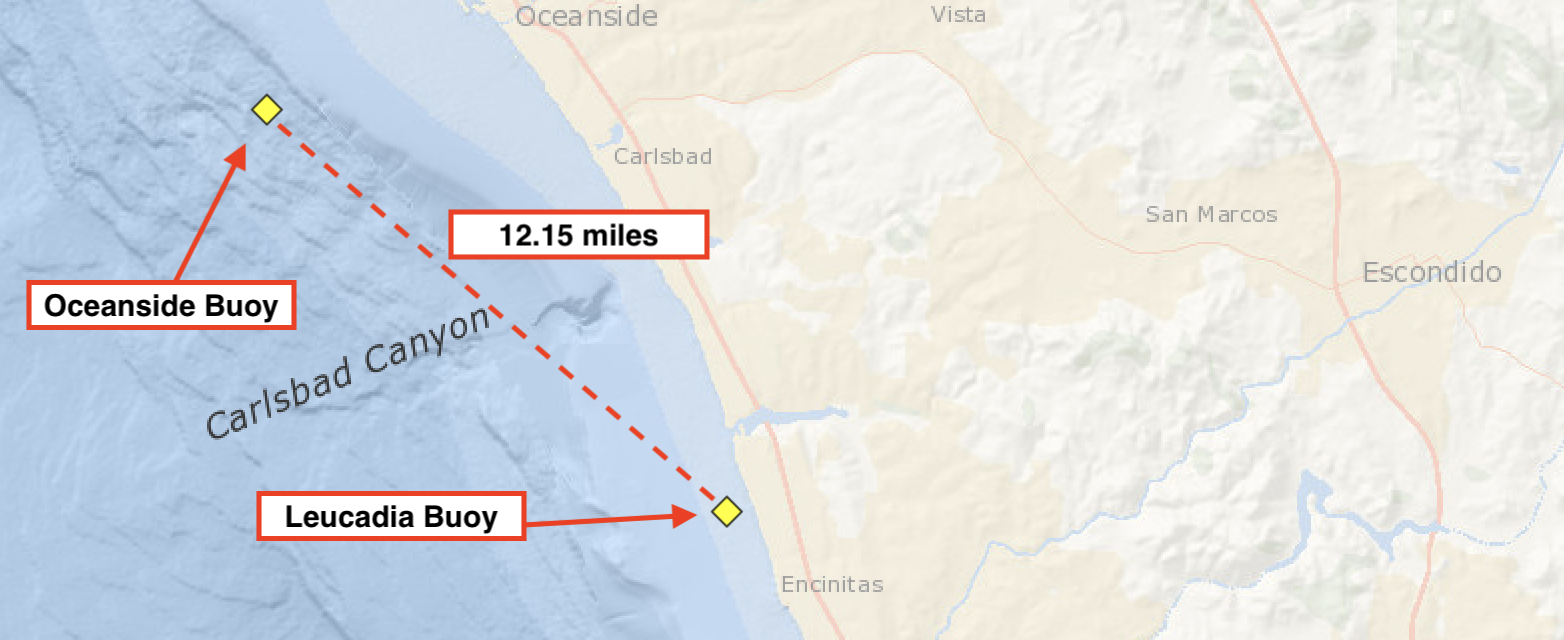
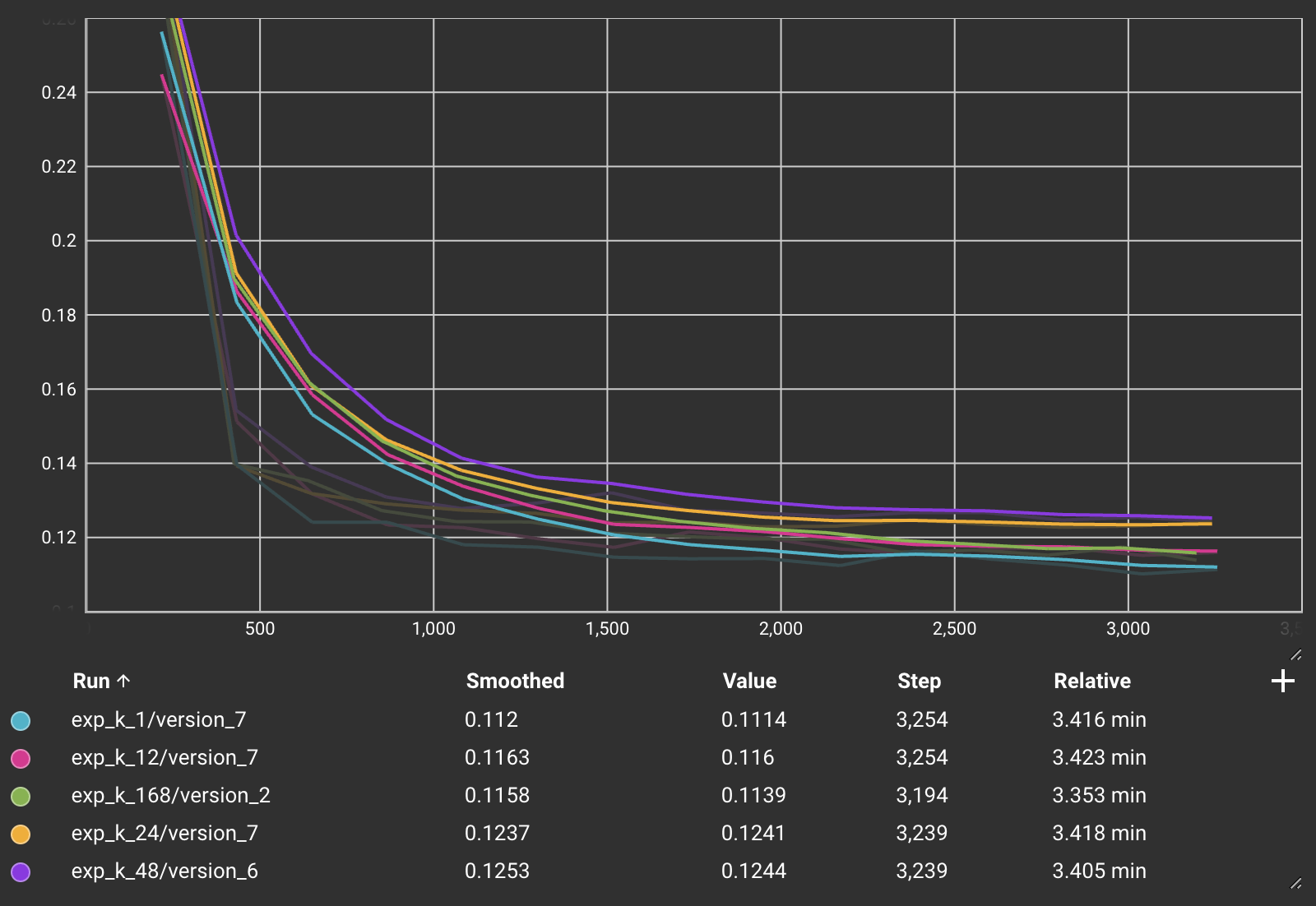
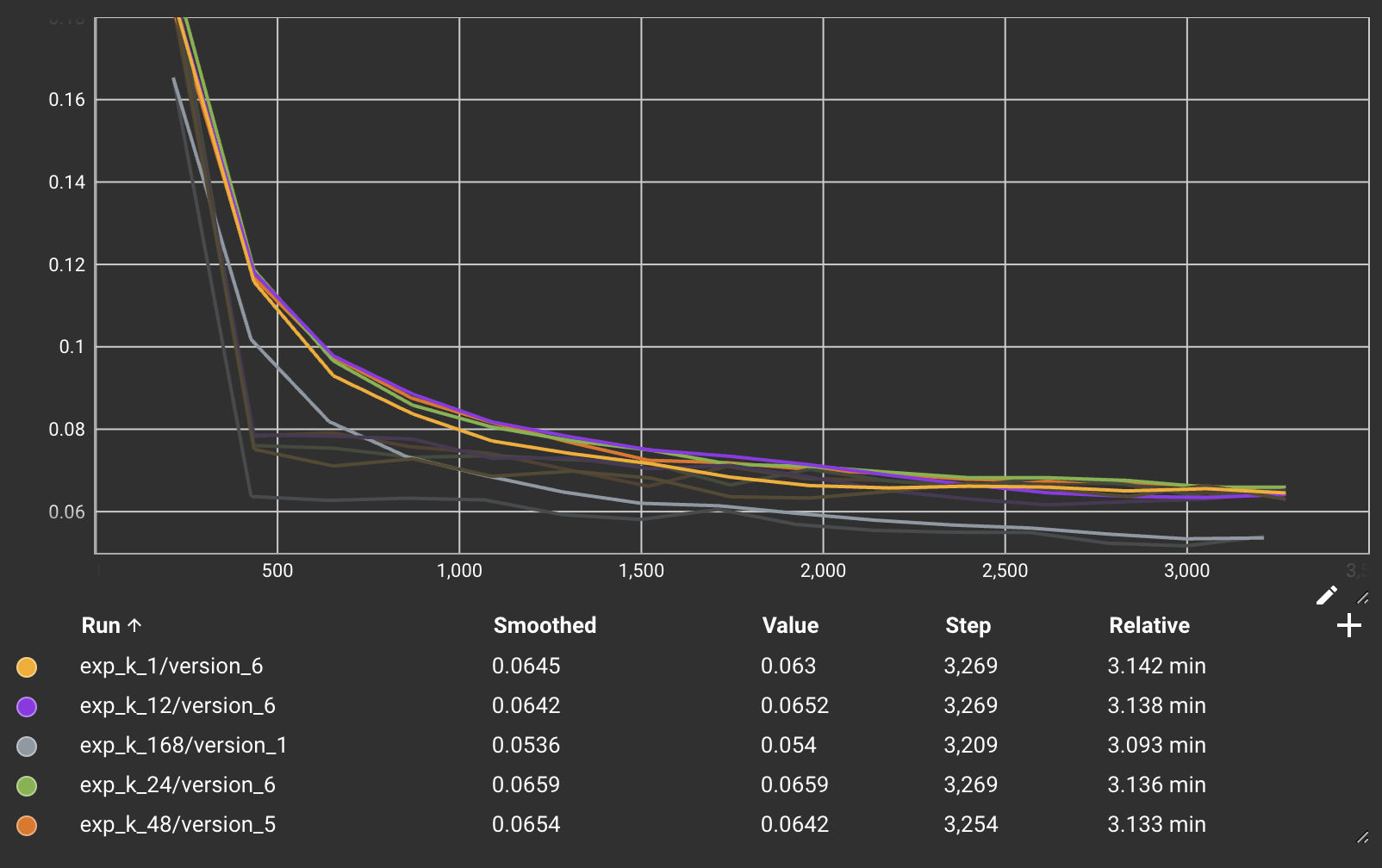
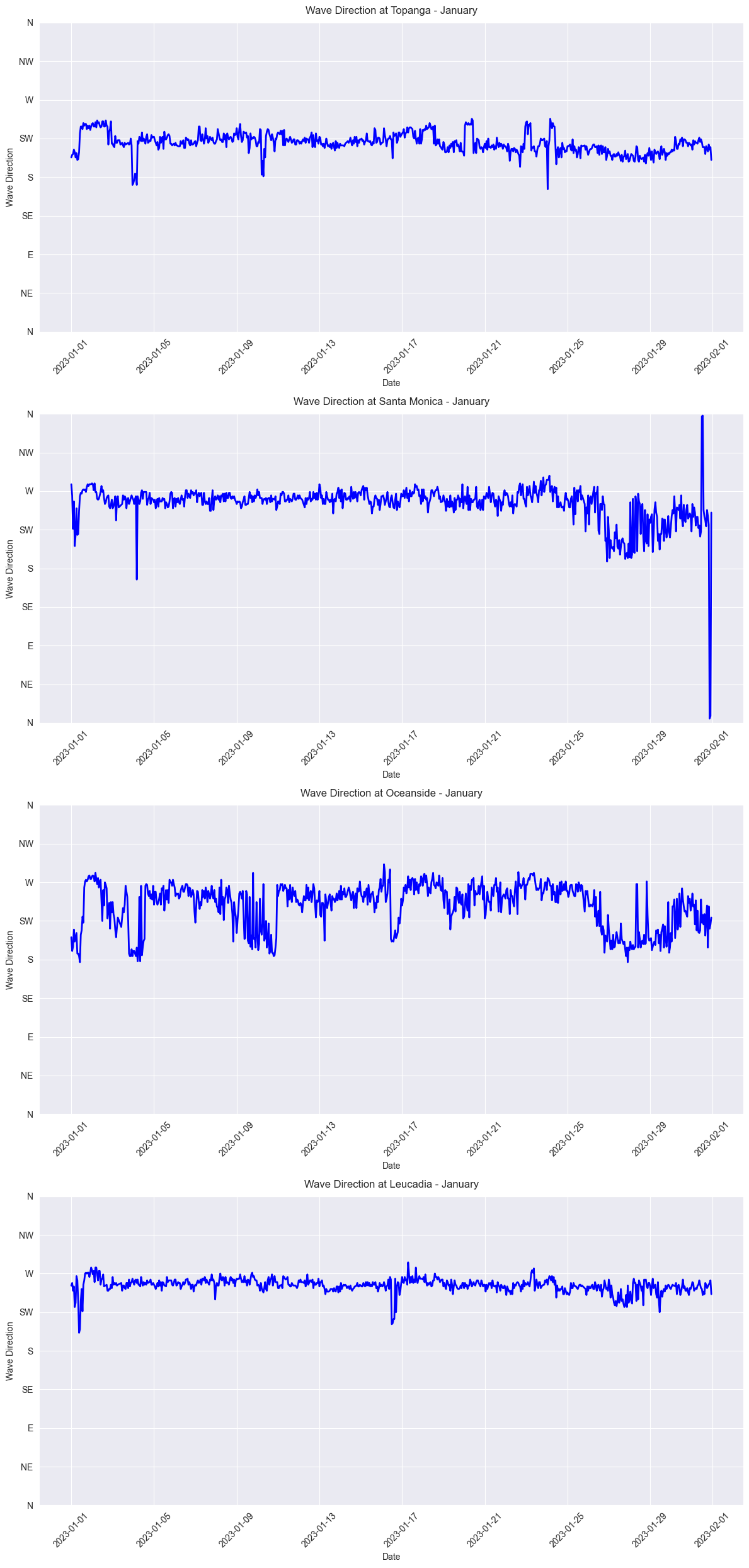 Wave directions during the month of January for each buoy
Wave directions during the month of January for each buoy